
Categories
Links
Easily load large amounts of client data into the Kurtosys App using supported file formats. The data is then consumed and loaded by Kurtosys-built loaders, and used in client documents, portals, or websites.
CSV (Comma Separated Values)
XML (eXtensible Markup Language)
JSON (JavaScript Object Notation)
XLSX (Excel Spreadsheet)
DOC/DOCX (Word documents)
PPT/PPTX (Powerpoint presentations)
JPEG, PNG, etc (Images)
Common identifiers include ISINs, Tickers, Fund IDs, CUSIPs, and Account IDs.
Each entity and benchmark must have a unique identifier, and there should be a logical mapping that links them together.
Each set of data should include a consistent date across all records.
This maintains uniformity across all datasets for the same reporting period. Consistency in reporting dates enables easy reference and alignment across multiple datasets.
ID | Name | Reporting Date | Value |
|---|---|---|---|
1 | Name A | 2023-12-31 | 100 |
2 | Name B | 2023-12-31 | 200 |
3 | Name C | 2023-12-31 | 300 |
ID | Name | Value | |
|---|---|---|---|
1 | Name A | 2023-12-31 | 100 |
2 | Name B | 12-31-2023 | 200 |
3 | Name C | 31/12/2023 | 300 |
Ensure that data structures remain consistent over time. Do not add, remove, or rearrange columns from one month to the next without notifying Kurtosys about the change.
When data structures remain unchanged, it simplifies the development of automated processes, prevents disruptions in data processing, and reduces the need for frequent adjustments which can become costly over time.
ID | Name | Reporting Date | Value |
|---|---|---|---|
1 | Name A | 2023-12-31 | 100 |
2 | Name B | 2023-12-31 | 200 |
3 | Name C | 2023-12-31 | 300 |
4 | Name D | 2023-12-31 | 250 |
ID | Name | Report Date | Value | Comment |
|---|---|---|---|---|
1 | Name A | 2023-12-31 | 100 | New |
2 | Name B | 2023-12-31 | Two hundred | Load |
3 | Name C | 2023-12-31 | 300 | Delete |
4 | Name D | 2023-12-31 | =100+150 | New |
It’s important to maintain consistency in data structures over time. One way to ensure this is by establishing consistent naming conventions for file names. This will help in correctly identifying files for processing.
Change File Naming Convention:
Ensure the file name remains unchanged between reporting cycles to prevent validation errors
Change File Type:
Ensure the file type remains unchanged between reporting cycles to prevent validation errors
Date received | File name | File type |
|---|---|---|
1 Apr ’23 | monthly_returns_20240331.csv | CSV |
1 May ’23 | monthly_returns_20240430.csv | CSV |
1 Jun ’23 | monthly_returns_20240531.csv | CSV |
Date received | File name | File type |
|---|---|---|
1 Apr ’23 | monthly_returns_20240331.xlsx | XLSX |
1 May ’23 | monthly_20240430.csv | CSV |
1 Jun ’23 | monthly_returns_.xls | XLS |
It is important to perform detailed checks on the information provided to ensure that it is accurate, complete, and trustworthy. This will help to spot and correct any mistakes, discrepancies or irregularities in the data. By validating the data against predetermined standards and guidelines, we can assure its dependability and appropriateness for examination and handling.
Validation checks can include:
It is recommended to avoid manual data processing, which increases the risk of errors and inconsistencies. Instead, automated processes should be used for successful data ingestion and loading.
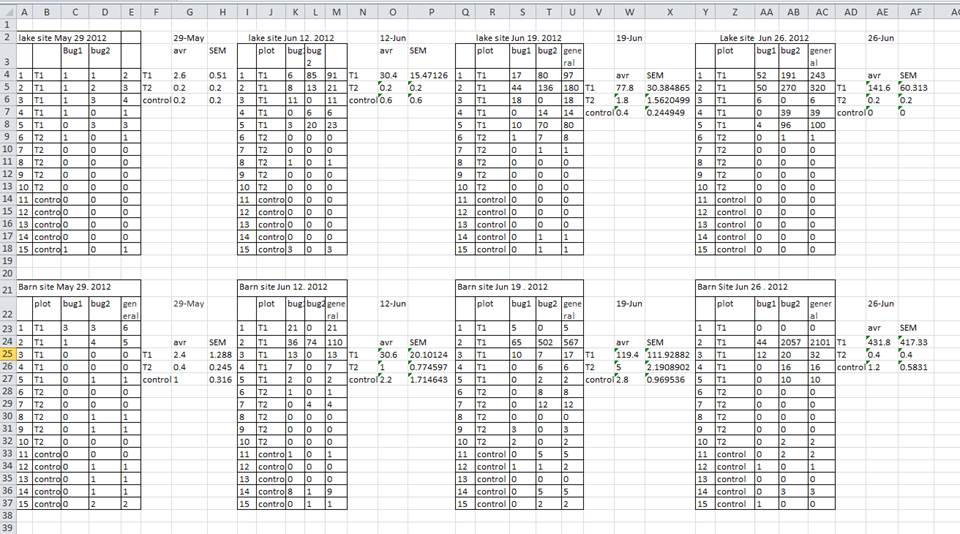
A common mistake is creating multiple data tables within a single spreadsheet as show in the image.
A computer will rigidly interpret anything in the same row as belonging to the same observation.
Rather consolidate the tables into one. This will ensure a consistent data structure, and avoid errors when looking up data from different tables.
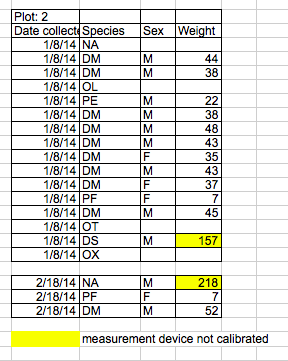
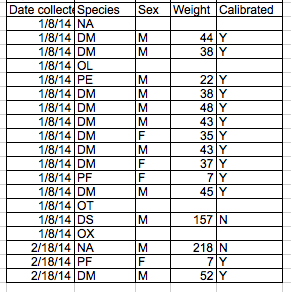
When working with data in a file, it is crucial to distinguish between a zero and a blank cell.
A zero represents a valid measurement, whereas a blank cell indicates that no measurement was taken. In such cases, the computer interprets the blank cell as an unknown value, also known as a null value.
It is important to accurately record zeros as zeros and null values as nulls. Any other substitution for null values should be avoided. The table below shows common substitutions that should not be used.
Data Value | Problem | Recommendation |
|---|---|---|
‘0’ | Indistinguishable from a true zero if used to fill blanks in the data | Avoid unless a true zero |
‘NA’, ‘na’, ‘N/A’ or similar | Causes problems with data-type validation (turns a numerical column into a text column) | Avoid – leave blank |
‘NULL’ | Can cause problems with data type validation | Avoid – leave blank |
‘No data’ | Can cause problems with data type validation | Avoid – leave blank |
‘-‘,’+’,’.’ | Can cause problems with data type validation | Avoid – leave blank |
‘ ‘ (An empty space) | Can cause problems with data type validation | Avoid – leave blank |
A common example of using formatting to convey information is to highlight cells in a specific color that you want to be dealt with differently than others.
Another example is to leave a blank row to indicate a separation in the data. However, it is important to note that both of these highlighting approaches can cause problems since they are undetectable to computers.
When formatting a worksheet, avoid merging cells and using borders to separate data as it can impede the computer’s ability to see associations in the data. Merging cells cause column headers to disappear making it difficult to load data.
Borders alone will not be enough to indicate the start or end of a particular dataset. Rather place different tables on different tabs.
Units should be consistent and not included in data cells. Instead of noting “$5MM” in a cell, just write “5” and specify the unit in the column header or a separate column to avoid analysis complications.
For easy data analysis, use descriptive yet concise column names. Avoid spaces, numbers at the start, and special characters.
Use underscores or CamelCase for multi-word names to maintain readability and data integrity.
Avoid | Alternative | Reason |
|---|---|---|
MaxPercentage ( % ) | max_percentage | Uses a special character ( % ) |
Mean_growth/year | mean_yr_growth | Uses a special character ( / ) |
Annual returns | annual_returns | Uses a blank character |
3 Year Returns | returns_3yr | Uses a blank character and starts with a number |